library("tidyverse")
library("mlr3verse")
library("Cubist") # Cubist ML algorithm
library("ranger") # Random Forest ML algorithm
library("glmnet") # Elastic net ML Algorithm
library("future") # Parallel processing
library("yardstick") # Additional metrics
library("mlr3extralearners") # Additional models and features
library("iml") # Feature importance3 Machine Learning
In this section, we introduce the machine learning pipeline for estimating soil properties using soil NIR data. We will use the mlr3 framework for predicting Soil Organic Carbon (SOC). We will train a predictive model using the NIR spectra from US soil samples, while the testing of the model’s generalization happens on African soil samples.
Note
The train.csv and test.csv are prepared in the previous section: 2.6 Preparing machine learning dataset.
The mlr3 framework is well presented in Bischl et al. (2024).
You can also find a lot of interesting video tutorials on machine learning in OpenGeoHub training videos.
A list of all required packages for this section is provided in the following code chunk:
Except for mlr3extralearners, you can install all the above packages using install.packages(). In this case, follow the intructions on mlr3extralearners GitHub repository:
# latest GitHub release
remotes::install_github("mlr-org/mlr3extralearners@*release")Please, set the working directory (or load an RStudio project) in your local machine:
my.wd <- "~/projects/local-files/soilspec_training"
# Or within an RStudio project
# my.wd <- getwd()3.1 Introduction to mlr3 framework
We introduce novel principles of the mlr3 framework using the first chapter of the official mlr3 book (Kotthoff et al. 2024).
(…) The mlr3 package and the wider mlr3 ecosystem provide a generic, object-oriented, and extensible framework for regression, classification, and other machine learning tasks for the R language. (…) We build on R6 for object orientation and data.table to store and operate on tabular data.

The most convenient way how to load the whole mlr3 ecosystem is to load the mlr3verse package.
#install.packages("mlr3verse")
library("mlr3verse")
library("tidyverse")
# Loading train and test data
train_matrix <- read_csv(file.path(my.wd, "train.csv"))
test_matrix <- read_csv(file.path(my.wd, "test.csv"))What is R6?
Note
R6 is one of R’s more recent paradigms for object-oriented programming.
Objects are created by constructing an instance of an R6::R6Class variable using the $new() initialization method. For example, say we have used a mlr3 class TaskRegr, then TaskRegr$new(id = "NIR_spectral", backend = train_matrix, target = "oc_usda.c729_w.pct") would create a new object of class TaskRegr and sets the id , backendand target fields that encapsulates mutable state of the object.
Methods allow users to inspect the object’s state, retrieve information, or perform an action that changes the internal state of the object. For example$set_col_roles() method sets the special roles such as ID or blocking during resampling of the columns.
# Creating an example object
example_object <- TaskRegr$new(id = "NIR_spectral",
backend = train_matrix,
target = "oc_usda.c729_w.pct")
# Access to the $id field
example_object$id[1] "NIR_spectral"# Calling methods of the object
example_object$set_col_roles("id.sample_local_c", role = "name")
example_object$set_col_roles("location.country_iso.3166_txt", role = "group")
example_object$col_roles$feature
[1] "pc_1" "pc_2" "pc_3" "pc_4" "pc_5" "pc_6" "pc_7" "pc_8"
$target
[1] "oc_usda.c729_w.pct"
$name
[1] "id.sample_local_c"
$order
character(0)
$stratum
character(0)
$group
[1] "location.country_iso.3166_txt"
$weight
character(0)mlr3 Utilities
mlr3 uses convenience functions called helper or sugar functions to create most of the objects. For example, lrn("regr.rpart") returns the decision tree learner without having to explicitly create a new R6 object.
mlr3 uses Dictionaries to store R6 classes. For example lrn("regr.rpart") is a wrapper around mlr_learners$get("regr.rpart"). You can see an overview of available learners by calling the sugar function without any arguments, i.e. lrn().
3.2 Inspecting data and a baseline model
Soil organic carbon (SOC) is a measurable component of soil organic matter. Organic matter makes up just a small part of soil’s mass and has an important role in the physical, chemical and biological function of agricultural soils. SOC is represented in percent units (0-100%) and have a highly right skewed probability distribution because SOC makes up just 2-10% of most soil’s mass. The higher content is typical mainly for Organic soils i. e. peatbogs. Therefore SOC is often modeled in a log-scale to penalize for the higher SOC content that is a minor part of the data. Let’s see if its is our case too.
hist(train_matrix$oc_usda.c729_w.pct, breaks = 100)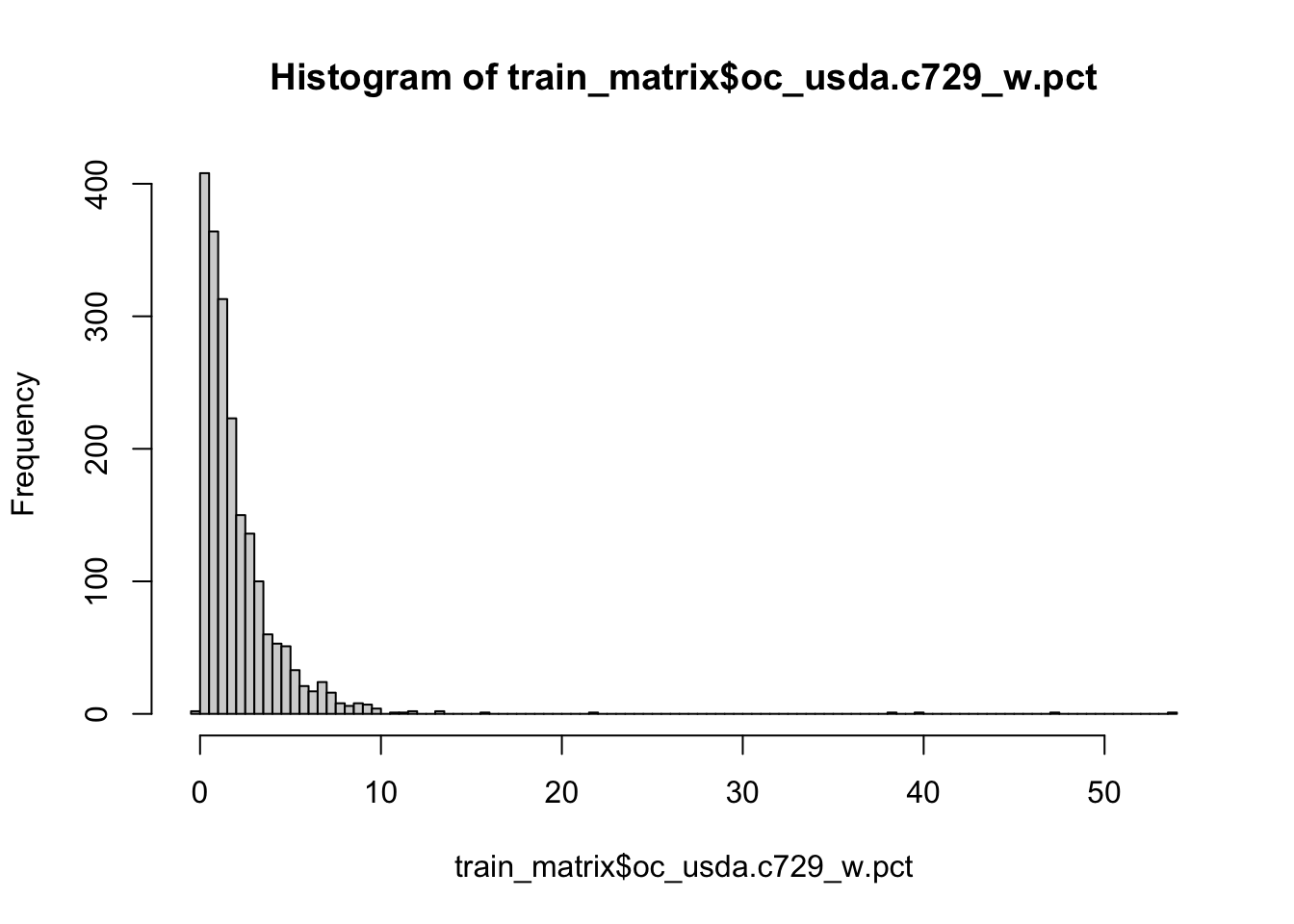
Yes, it is. So lets apply log1p function to SOC values of our train and test set. log1p function calculates natural logarithm of the values with an offset of 1 (which avoid negative log values).
train_matrix$oc_usda.c729_w.pct <- log1p(train_matrix$oc_usda.c729_w.pct)
test_matrix$oc_usda.c729_w.pct <- log1p(test_matrix$oc_usda.c729_w.pct)
hist(train_matrix$oc_usda.c729_w.pct, breaks = 100)
It is a good practice to train a dummy model as a baseline to track the predictive power increment of our ML models. But lets first create our ML task using mlr3 syntax to follow the logic of the framework.
We will use the convenient method as_task_regr() to convert data object to a TaskRegr class. We need to set argument target specifying our target variable and id of the task. We will also set special role "name" (Row names/observation labels) to the "id.sample_local_c" column.
# Setting a seed for reproducibility
set.seed(349)
# Create a task
train_matrix <- train_matrix %>%
select(-location.country_iso.3166_txt)
task_neospectra <- as_task_regr(train_matrix,
target = "oc_usda.c729_w.pct",
id = "NIR_spectral")
# Set row names role to the id.sample_local_c column
task_neospectra$set_col_roles("id.sample_local_c", roles = "name")
task_neospectra<TaskRegr:NIR_spectral> (2016 x 9)
* Target: oc_usda.c729_w.pct
* Properties: -
* Features (8):
- dbl (8): pc_1, pc_2, pc_3, pc_4, pc_5, pc_6, pc_7, pc_8We will train a dummy model that always predicts new values as the mean of the target variable. The dummy model is called "regr.featureless" in the mlr3 dictionary. We can call lrn("regr.featureless") to create a Learner class R6 object with no explicit programming.
# Load featureless learner
# featureless = always predicts new values as the mean of the dataset
lrn_baseline <- lrn("regr.featureless")
# Only one hyperparameter can be set: robust = calculate mean if false / calculate median if true
# lrn_baseline$param_set
# Train learners using $train() method
lrn_baseline$train(task_neospectra)Now we can calculate the Root Mean Square Error (RMSE), Mean Error (Bias), and Coefficient of Determination (R2) to assess the goodness-of-fit of a model.
Root Mean Square Error (RMSE)
RMSE is calculated as a square root of the mean of the squared differences between predicted and expected values. The units of the RMSE are the same as the original units of the target value that is being predicted. RMSE of the perfect match is 0 (Wikipedia).
Mean Error (Bias)
Bias is calculated as the average of error values. Good predictions score close to 0 (Wikipedia).
Coefficient of Determination (R2)
R2 is the proportion of the variation in the dependent variable that is predictable from the independent variable(s) (Wikipedia). In the best case, the modeled values exactly match the observed values, which results in residual sum of squares 0 and R2 = 1. A baseline model, which always predicts mean, will have R2 <= 0 when a non-linear function is used to fit the data (Cameron and Windmeijer 1997).
We will use msrs sugar function featured in the mlr3 dictionary to create an object containing a list of class Measures objects: c("regr.rmse", "regr.bias", "regr.rsq").
# Setting a seed for reproducibility
set.seed(349)
# Define goodness-of-fit metrics
measures <- msrs(c("regr.rmse", "regr.bias", "regr.rsq"))
# Predict on a new data using $predict_newdata() method
pred_baseline <- lrn_baseline$predict_newdata(test_matrix)
# Evaluation on the new data applying $score() method
pred_baseline$score(measures) regr.rmse regr.bias regr.rsq
0.5765752 -0.4409049 -1.4082480 3.3 Simple benchmarking
We have the baseline for now. So we can start selecting the best performing ML model. How does one selects the best performing model for a specific task? One can compare estimated generalization error (accuracy) of the models using a Cross-Validation (CV) scheme.
Benchmarking is easy in mlr3 framework thanks to predefined object classes, sugar functions and dictionaries. One has to define the set of learners for benchmarking using lrns() and other dictionaries. The second step is to define a Resample object that encapsulates the CV. We will use 10-fold CV for now.
lrn_cv <- lrns(c("regr.ranger", "regr.cv_glmnet", "regr.cubist"))
cv10 <- rsmp("cv", folds = 10)We can pass both objects to benchmark_grid() together with the task for constructing an exhaustive design that describe all combinations of the learners, tasks, and resamplings to be used in a benchmark experiment. The benchmark experiment is conducted with benchmark(). The results are stored in the object of the BenchmarkResult class. One can access the results of benchmarking applying $score() or $aggregate() methods on the object. We can pass Measures object storing the selected metrics in the functions (Casalicchio and Burk 2024).
bench_cv_grid <- benchmark_grid(task_neospectra, lrn_cv, cv10)
bench_cv <- benchmark(bench_cv_grid)# Check the results of each fold using $score()
bench_cv$score(measures) nr task_id learner_id resampling_id iteration regr.rmse
1: 1 NIR_spectral regr.ranger cv 1 0.3649898
2: 1 NIR_spectral regr.ranger cv 2 0.3006496
3: 1 NIR_spectral regr.ranger cv 3 0.3258538
4: 1 NIR_spectral regr.ranger cv 4 0.2907615
5: 1 NIR_spectral regr.ranger cv 5 0.2974990
6: 1 NIR_spectral regr.ranger cv 6 0.3072503
7: 1 NIR_spectral regr.ranger cv 7 0.3499998
8: 1 NIR_spectral regr.ranger cv 8 0.2906318
9: 1 NIR_spectral regr.ranger cv 9 0.3277458
10: 1 NIR_spectral regr.ranger cv 10 0.3218786
11: 2 NIR_spectral regr.cv_glmnet cv 1 0.4051167
12: 2 NIR_spectral regr.cv_glmnet cv 2 0.3385091
13: 2 NIR_spectral regr.cv_glmnet cv 3 0.3778171
14: 2 NIR_spectral regr.cv_glmnet cv 4 0.3261307
15: 2 NIR_spectral regr.cv_glmnet cv 5 0.3500118
16: 2 NIR_spectral regr.cv_glmnet cv 6 0.3436996
17: 2 NIR_spectral regr.cv_glmnet cv 7 0.3914502
18: 2 NIR_spectral regr.cv_glmnet cv 8 0.3541713
19: 2 NIR_spectral regr.cv_glmnet cv 9 0.3619121
20: 2 NIR_spectral regr.cv_glmnet cv 10 0.3576874
21: 3 NIR_spectral regr.cubist cv 1 0.3185123
22: 3 NIR_spectral regr.cubist cv 2 0.3132990
23: 3 NIR_spectral regr.cubist cv 3 0.3505592
24: 3 NIR_spectral regr.cubist cv 4 0.3086609
25: 3 NIR_spectral regr.cubist cv 5 0.3284882
26: 3 NIR_spectral regr.cubist cv 6 0.3810715
27: 3 NIR_spectral regr.cubist cv 7 0.3222047
28: 3 NIR_spectral regr.cubist cv 8 0.2952791
29: 3 NIR_spectral regr.cubist cv 9 0.3508014
30: 3 NIR_spectral regr.cubist cv 10 0.3258893
nr task_id learner_id resampling_id iteration regr.rmse
regr.bias regr.rsq
1: 0.018460577 0.6690143
2: -0.003384883 0.7044709
3: -0.054288455 0.6879432
4: 0.006812642 0.7066220
5: 0.009398130 0.6984627
6: -0.031894466 0.6582898
7: 0.006662112 0.6672526
8: 0.018934061 0.7344966
9: 0.005716332 0.6528675
10: 0.006377608 0.6578186
11: 0.014720522 0.5922367
12: -0.004521355 0.6253552
13: -0.046789058 0.5804812
14: 0.032698578 0.6309058
15: 0.002219404 0.5826163
16: -0.047365437 0.5724062
17: 0.021762050 0.5837712
18: -0.002904861 0.6057149
19: 0.018311328 0.5767206
20: 0.009944302 0.5774488
21: 0.021964764 0.7479421
22: -0.020419967 0.6790797
23: -0.049449510 0.6388306
24: 0.009858424 0.6693892
25: 0.006786581 0.6323710
26: -0.067770136 0.4743624
27: 0.007386198 0.7180041
28: -0.011673296 0.7259378
29: -0.001245794 0.6023112
30: -0.005702877 0.6492381
regr.bias regr.rsq
Hidden columns: uhash, task, learner, resampling, prediction# Check the aggregated results of the models using $aggregate()
bench_cv$aggregate(measures) nr task_id learner_id resampling_id iters regr.rmse regr.bias
1: 1 NIR_spectral regr.ranger cv 10 0.3177260 -0.0017206343
2: 2 NIR_spectral regr.cv_glmnet cv 10 0.3606506 -0.0001924528
3: 3 NIR_spectral regr.cubist cv 10 0.3294766 -0.0110265614
regr.rsq
1: 0.6837238
2: 0.5927657
3: 0.6537466
Hidden columns: resample_result3.4 Simple tuning
Parameters x Hyperparameters
Machine learning algorithms usually include parameters and hyperparameters. Parameters are the model coefficients or weights or other information that are determined by the learning algorithm based on the training data. In contrast, hyperparameters, are configured by the user and determine how the model will fit its parameters, i.e., how the model is built. The goal of hyperparameter optimization (HPO) or model tuning is to find the optimal configuration of hyperparameters of a machine learning algorithm for a given task. (…) (Becker, Schneider, and Fischer 2024).
We will practice HPO with a simple model tuning using the cubist model learner. For this, we will randomly search for the best pair of comitees (a boosting-like scheme where iterative model trees are created in sequence) and neighbors (how many similar training points are used for determining the average of terminal points) hyperparameters.
# Define search space for committees and neighbors inside the Learner object using to_tune function
lrn_cubist <- lrn("regr.cubist",
committees = to_tune(1, 20),
neighbors = to_tune(0, 5))
# Setting a seed for reproducibility
set.seed(349)
# Define tuning instance using tune() helper function
# tune() function will automatically calls $optimize() method of the instance
simple_tune <- tune(
method = tnr("random_search"), # Picking random combinations of hyperparameters from the search space
task = task_neospectra, # The task with training data
learner = lrn_cubist, # Learner algorithm
resampling = cv10, # Apply 10-fold CV to calculate the evaluation metrics
measures = msr("regr.rmse"), # Use RMSE to select the best set of hyperparameters
term_evals = 10 # Terminate tuning after testing 10 combinations
)# Exploring tuning results
simple_tune$result committees neighbors learner_param_vals x_domain regr.rmse
1: 11 5 <list[2]> <list[2]> 0.29756423.5 Combining benchmarking and tuning
It is a standard practice to combine tuning and benchmarking while searching for the best model.
Tip
When performing both operations simultaneously, it is a good practice to implement nested resampling to get a really robust estimate of the generalization error. This means that we implement inner CV for tuning models and outer CV to benchmark tuned models. We can implement it easily in mlr3 framework using the previous code and handy functions as indicated in the Nested Resampling section.
# Showing dictionary of available pre-trained tuning spaces
as.data.table(mlr_tuning_spaces)[,.(label)] label
1: Classification GLM with Default
2: Classification GLM with RandomBot
3: Classification GLM with RandomBot
4: Classification KKNN with Default
5: Classification KKNN with RandomBot
6: Classification KKNN with RandomBot
7: Classification Ranger with Default
8: Classification Ranger with RandomBot
9: Classification Ranger with RandomBot
10: Classification Rpart with Default
11: Classification Rpart with RandomBot
12: Classification Rpart with RandomBot
13: Classification SVM with Default
14: Classification SVM with RandomBot
15: Classification SVM with RandomBot
16: Classification XGBoost with Default
17: Classification XGBoost with RandomBot
18: Classification XGBoost with RandomBot
19: Regression GLM with Default
20: Regression GLM with RandomBot
21: Regression GLM with RandomBot
22: Regression KKNN with Default
23: Regression KKNN with RandomBot
24: Regression KKNN with RandomBot
25: Regression Ranger with Default
26: Regression Ranger with RandomBot
27: Regression Ranger with RandomBot
28: Regression Rpart with Default
29: Regression Rpart with RandomBot
30: Regression Rpart with RandomBot
31: Regression SVM with Default
32: Regression SVM with RandomBot
33: Regression SVM with RandomBot
34: Regression XGBoost with Default
35: Regression XGBoost with RandomBot
36: Regression XGBoost with RandomBot
labelRunning internal (inner) cross-validation for independent model optimization.
# Selecting the spaces using sugar function ltss()
# Not available for cubist
spaces <- ltss(c("regr.ranger.default", "regr.glmnet.default"))
# Creating a list of learners and an empty list to write tuned learners
lrn_cv <- lrns(c("regr.ranger", "regr.glmnet"))
lrn_cv_tuned <- list()
# To avoid most of the logs
lgr::get_logger("mlr3")$set_threshold("warn")
# For loop to tune hyperparameters of every learner using random search
i=1
for(i in 1:length(lrn_cv)){
# Using multiple cores for tuning each model
future::plan("multisession")
set.seed(349)
instance <- tune(task = task_neospectra,
method = tnr("random_search"),
learner = lrn_cv[[i]],
resampling = cv10,
measures = msr("regr.rmse"),
term_evals = 10,
search_space = spaces[[i]])
# Writing tuned hyperparameters
lrn_cv_tuned[[i]] <- lrn_cv[[i]]
lrn_cv_tuned[[i]]$param_set$values <- instance$result_learner_param_vals
}
# Close parallel connection
future:::ClusterRegistry("stop")
# Adding previously tuned cubist model to the list for benchmarking
# Create a new instance of the cubist model
lrn_cubist_tuned <- lrn("regr.cubist")
# Set the best performing hyperparameters to the new instance
lrn_cubist_tuned$param_set$values <- simple_tune$result_learner_param_vals
# Bind it to the tuned models lists
lrn_cv_tuned <- c(lrn_cv_tuned, lrn_cubist_tuned)Now we can perform a complete benchmark using outer cross-validation.
# Creating a benchmark grid
bench_cv_grid <- benchmark_grid(task_neospectra, lrn_cv_tuned, cv10)
# Implementing bechmarking using multiple cores
future::plan("multisession")
bench_cv <- benchmark(bench_cv_grid)
future:::ClusterRegistry("stop")# Evaluating the results
bench_cv$aggregate(measures) nr task_id learner_id resampling_id iters regr.rmse regr.bias
1: 1 NIR_spectral regr.ranger cv 10 0.3120866 -1.023284e-03
2: 2 NIR_spectral regr.glmnet cv 10 0.3532389 6.146641e-05
3: 3 NIR_spectral regr.cubist cv 10 0.2966997 3.613205e-03
regr.rsq
1: 0.6955395
2: 0.6101215
3: 0.7242271
Hidden columns: resample_resultWe can see that the cubist model works best. So lets test the tuned cubist model on our test set.
We can get the real generalization error of the best performing model by training a new model instance on the whole dataset and calculating the error metrics on the test set.
# New Cubist learner
lrn_cubist_tuned <- lrn("regr.cubist")
# Setting the best HPs
lrn_cubist_tuned$param_set$values <- lrn_cv_tuned[[3]]$param_set$values # Cubist is the third learner in the list
# Fitting with whole train set
lrn_cubist_tuned$train(task_neospectra)
# Predicting on test set
pred_cubist_response <- lrn_cubist_tuned$predict_newdata(test_matrix)
# Final goodness-of-fit metrics
pred_cubist_response$score(measures) regr.rmse regr.bias regr.rsq
0.24650192 0.06596374 0.55982045 3.6 Model interpretation
Model interpretation helps us to understand which features contribute most to the predictive performance of the model. There are many ways in doing this, and we recommend visiting Chapter 12 of the MLR3 book to learn more about the possibilities.
In this section, we will explore the the permutation feature importance (PFI). This methods randomly shuffles observed values for every single feature and save the model performance change before and after permuting them. Important features cause a significant change of performance when shuffled. It is a very popular method because it is model agnostic and allow the quick inspection of models by a simple procedure.
Let’s explore the importance of our tuned cubist model. We use 10 repetitions to be able to capture the range of the importance from several random shuffles. You can increase this number to make it more robust. As we are working with a regression task, the metric that capture the importance change is the mean squared error (mse).
# Grabbing the features in train data
model_predictors <- task_neospectra$data(cols = task_neospectra$feature_names)
# Grabbing the outcome in train data
model_outcome <- task_neospectra$data(cols = task_neospectra$target_names)
# Building a predictor object for importance evaluation
predictor = Predictor$new(lrn_cubist_tuned,
data = model_predictors,
y = model_outcome)
importance = FeatureImp$new(predictor, loss = "mse", n.repetitions = 10)
importance$plot()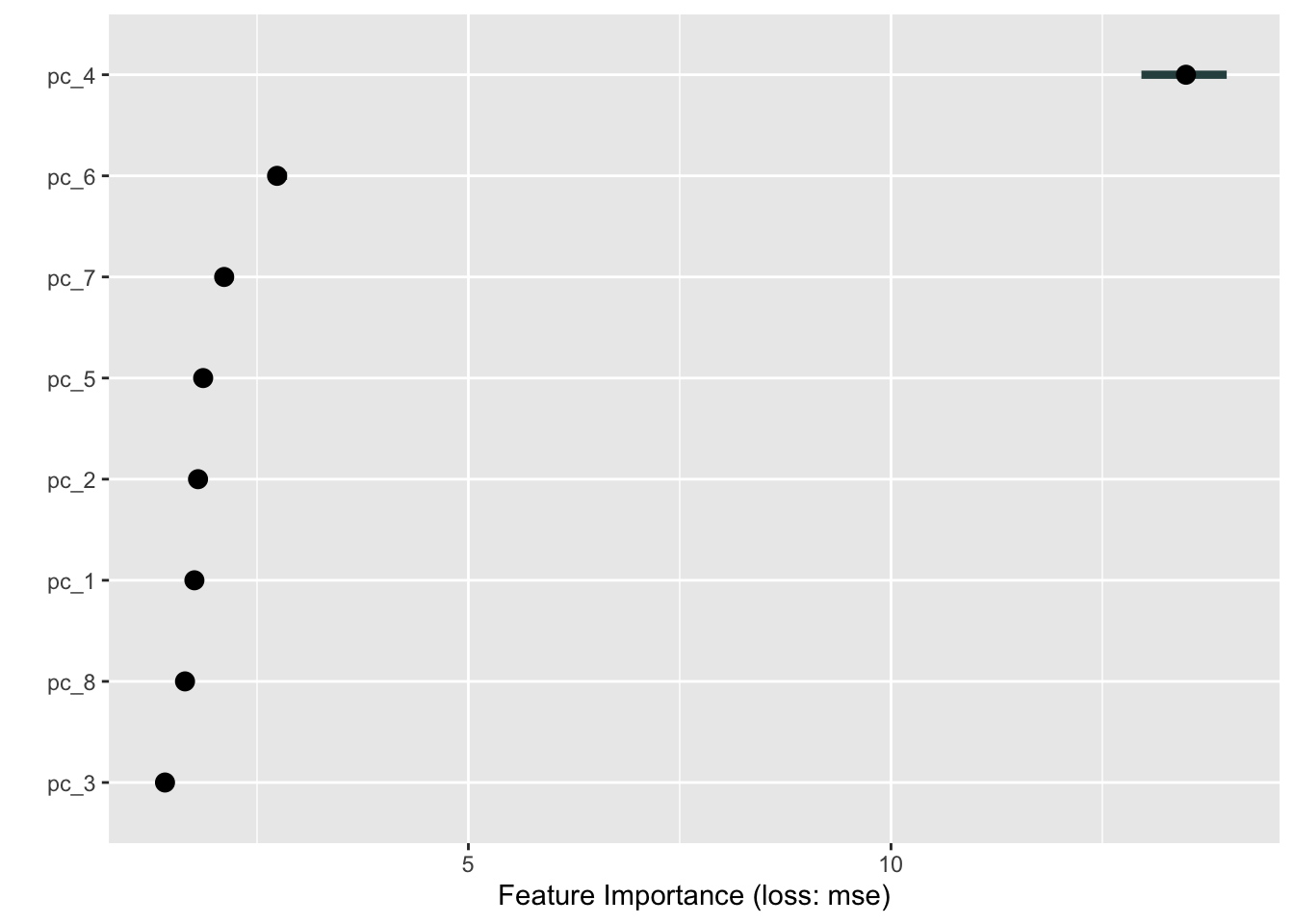
Therefore, pc4 is largely the most important feature for SOC prediction. One can further dive into the pc4 composition to see which spectral features are being represented by the loadings of this principal component.
3.7 Additional accuracy assessment
We can get the observed and predicted values for creating an accuracy plot.
accuracy.data <- tibble(id = test_matrix$id.sample_local_c,
observed = pred_cubist_response$data$truth,
predicted = pred_cubist_response$data$response)
ggplot(accuracy.data) +
geom_point(aes(x = observed, y = predicted)) +
geom_abline(intercept = 0, slope = 1) +
theme_light()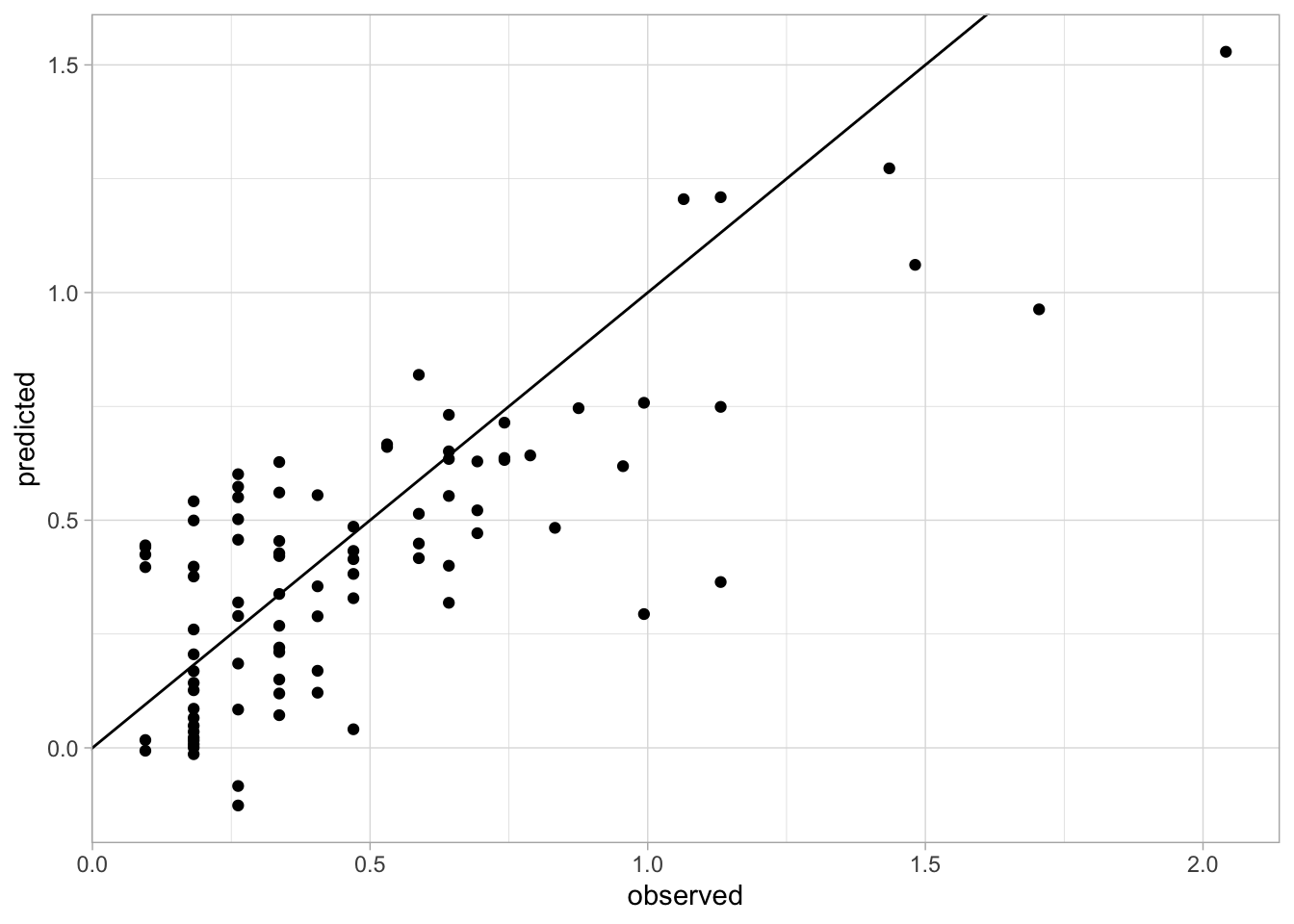
We can also use yardstick package to calculate additional goodness-of-fit metrics, like Lin’s Concordance Correlation Coefficient (CCC) and Ratio of Performance to the Interquartile Range (RPIQ).
Lin’s Concordance Correlation Coefficient (CCC)
CCC measures the agreement between between observed and predicted values, taking in consideration the bias (deviation from the 1:1 perfect agreement line). Scores close to 1 represent the best case. (Wikipedia).
Ratio of Performance to the Interquartile Range (RPIQ)
RPIQ measures the consistency of the model by taking into consideration the original variability (Interquartile Range) divided by the predicted mean error (RMSE) and is more easily comparable across distinct studies (Reference).
library("yardstick")
# Calculating metrics
accuracy.metrics <- accuracy.data %>%
summarise(n = n(),
rmse = rmse_vec(truth = observed, estimate = predicted),
bias = msd_vec(truth = observed, estimate = predicted),
rsq = rsq_vec(truth = observed, estimate = predicted),
ccc = ccc_vec(truth = observed, estimate = predicted, bias = T),
rpiq = rpiq_vec(truth = observed, estimate = predicted))
accuracy.metrics# A tibble: 1 × 6
n rmse bias rsq ccc rpiq
<int> <dbl> <dbl> <dbl> <dbl> <dbl>
1 90 0.247 0.0660 0.596 0.747 1.863.8 Uncertainty estimation
The 10-fold cross-validated predictions can be leveraged to estimate the error (absolute residual) of the calibration set and employ it to fit an uncertainty estimation model via the Split Conformal Prediction method.
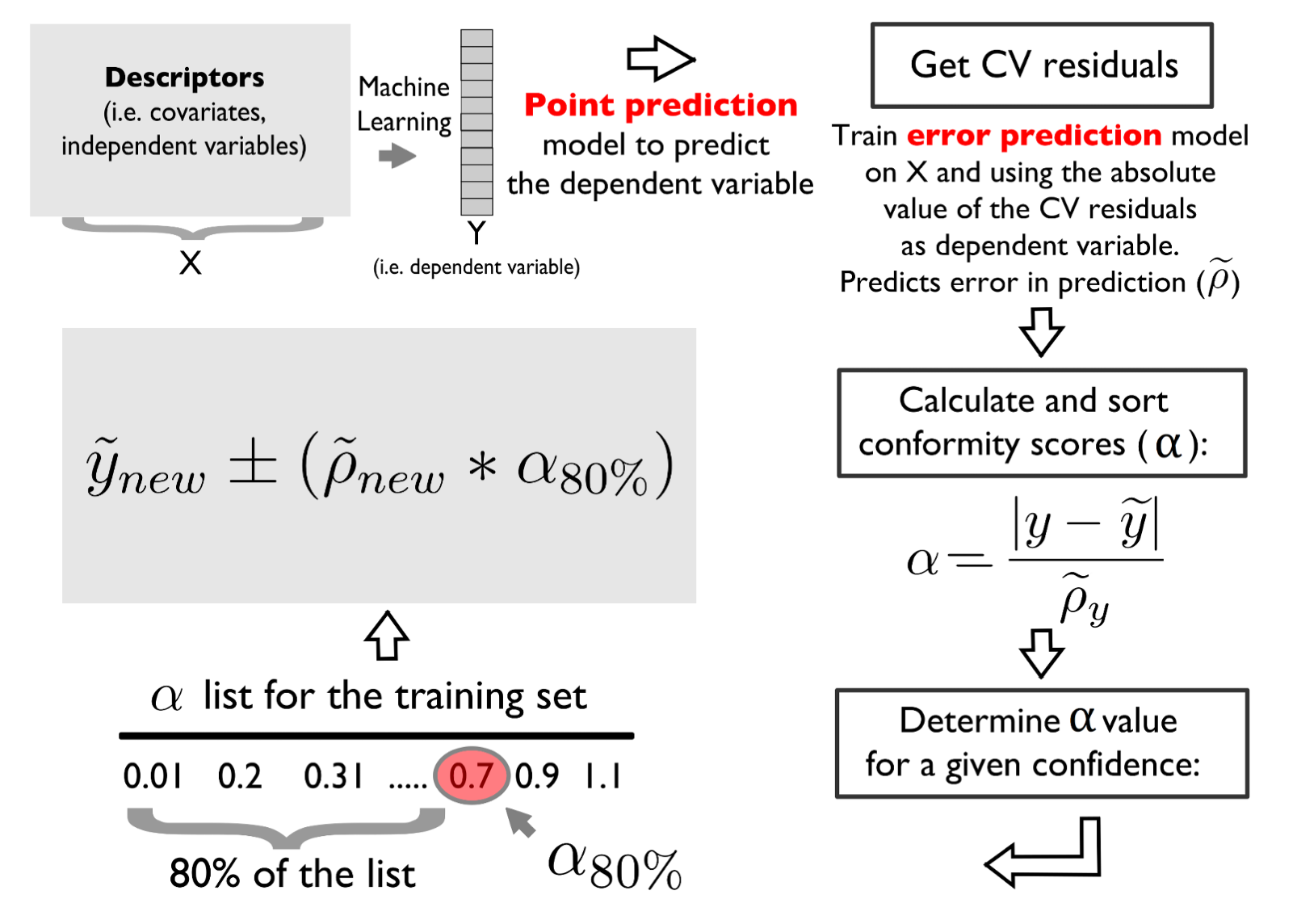
The error model is calibrated using the same fine-tuned structure of the response/target variable model.
Conformity scores are estimated for a defined confidence level, like 95% of confidence level or 68% (equivalent to one standard deviation).
In this part, we are going to produce 95% prediction intervals and we expect that the coverage statistics (also known as Prediciton Interval Coverage Percentage - PICP) is at least equal or higher than our predefined confidence level.
# Runing 10 CV with the Cubist tuned model
cv_results <- resample(task = task_neospectra,
learner = lrn_cubist_tuned,
resampling = rsmp("cv", folds = 10))
# Extracting the observed and predicted values within the folds
cv_results <- lapply(1:length(cv_results$predictions("test")), function(i){
as.data.table(cv_results$predictions("test")[[i]]) %>%
mutate(fold = i)})
cv_results <- Reduce(rbind, cv_results)
head(cv_results) row_ids truth response fold
1: 6 0.9966534 0.8774472 1
2: 9 0.7544304 0.9225900 1
3: 12 1.4923646 1.3901467 1
4: 21 1.8840347 1.0761806 1
5: 30 1.3099531 1.1165189 1
6: 33 1.3686394 1.4098105 1# Quick visualization
ggplot(cv_results) +
geom_point(aes(x = truth, y = response)) +
geom_abline(intercept = 0, slope = 1) +
theme_light()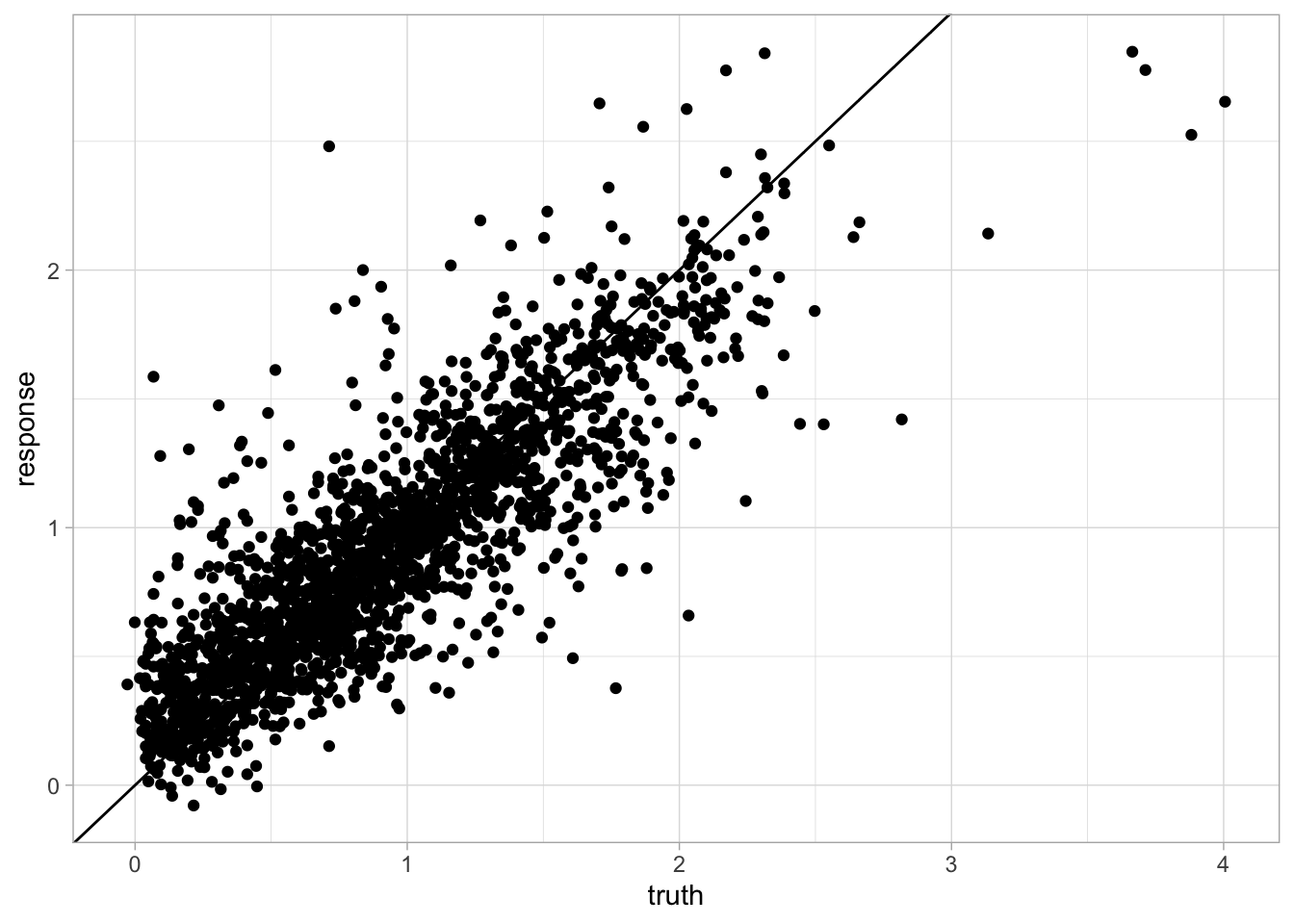
# Estimating the absolute error
cv_results <- cv_results %>%
mutate(error = abs(truth-response))
# Create a matrix with the same predictors as train_matrix and
# variable error as the new target
# you can View to see if the join worked well
error_matrix <- train_matrix %>%
mutate(row_ids = row_number()) %>%
left_join(cv_results, by = "row_ids")
# Simplifying with only necessary data
error_matrix <- error_matrix %>%
select(id.sample_local_c, error, starts_with("pc_"))
task_error <- as_task_regr(error_matrix,
target = "error",
id = "error_model")
# Set row names role to the id.sample_local_c column
task_error$set_col_roles("id.sample_local_c", roles = "name")
task_error<TaskRegr:error_model> (2016 x 9)
* Target: error
* Properties: -
* Features (8):
- dbl (8): pc_1, pc_2, pc_3, pc_4, pc_5, pc_6, pc_7, pc_8# Retrain the same model structure with the task_error
lrn_cubist_error = lrn("regr.cubist")
lrn_cubist_error$param_set$values = lrn_cubist_tuned$param_set$values
# Retrain
lrn_cubist_error <- lrn_cubist_tuned$train(task_error)
# Get the plain error predictions
error_predictions <- predict(lrn_cubist_error, newdata = as.data.table(task_error))
# Calculating the conformity scores (alpha) of the calibration set
error_matrix <- error_matrix %>%
select(-starts_with("pc_")) %>%
mutate(pred_error = error_predictions) %>%
mutate(alpha_scores = error/pred_error)
error_matrix# A tibble: 2,016 × 4
id.sample_local_c error pred_error alpha_scores
<dbl> <dbl> <dbl> <dbl>
1 100540 0.204 0.119 1.71
2 101337 1.14 0.493 2.31
3 101343 0.306 0.301 1.02
4 101372 0.00705 0.107 0.0657
5 102078 0.252 0.267 0.944
6 102085 0.119 0.191 0.625
7 102736 0.0272 0.198 0.138
8 102737 0.119 0.169 0.706
9 102744 0.168 0.136 1.24
10 102745 0.00363 0.101 0.0358
# ℹ 2,006 more rows# Sample correction and final conformity score
target_coverage = 0.95
n_calibration <- nrow(error_matrix)
corrected_quantile <- ((n_calibration + 1)*(target_coverage))/n_calibration
alpha_corrected <- quantile(error_matrix$alpha_scores, corrected_quantile)
# Predicting error on test set and calculating 95% prediction interval
# Predicting on test set
pred_cubist_error = lrn_cubist_error$predict_newdata(test_matrix)
pred_cubist_error<PredictionRegr> for 90 observations:
row_ids truth response
1 NA 0.0576321
2 NA 0.1179071
3 NA 0.4167666
---
88 NA 0.1223672
89 NA 0.1254210
90 NA 0.1608968# Final output
final.outputs <- accuracy.data %>%
mutate(error = pred_cubist_error$response) %>%
mutate(PI = error*alpha_corrected) %>%
mutate(lower_PI = predicted-PI,
upper_PI = predicted+PI) %>%
select(-error, -PI)
# Back-transforming all results because we have used log1p earlier
final.outputs <- final.outputs %>%
mutate(observed = expm1(observed),
predicted = expm1(predicted),
lower_PI = expm1(lower_PI),
upper_PI = expm1(upper_PI))
# Calculating coverage statistics
final.outputs <- final.outputs %>%
mutate(covered = ifelse(observed >= lower_PI & observed <= upper_PI, TRUE, FALSE),
wis = ifelse(observed < lower_PI,
(upper_PI-lower_PI)+(2/(1-target_coverage))*(lower_PI-observed),
ifelse(observed > upper_PI,
(upper_PI-lower_PI)+(2/(1-target_coverage))*(observed-upper_PI),
upper_PI-lower_PI)))
Note
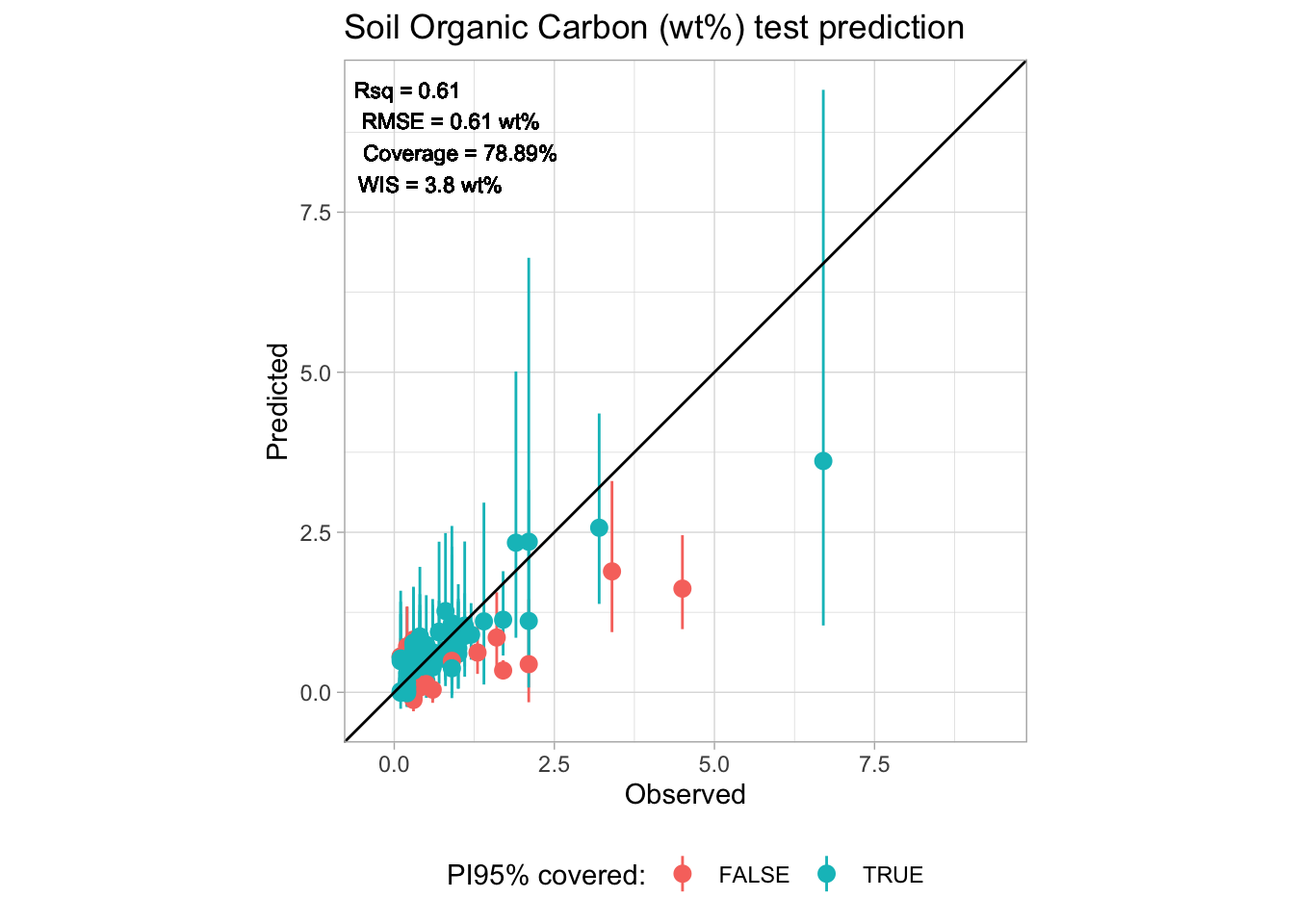
We don’t match 95% prediction interval (PI95%) probably because of the violation of the Exchangeability assumption, i.e, the train and test data might not be identically distributed. This might have happened because the test set does not come from the same geographical region and original spectral library, but split conformal prediction method still does a decent job for deriving the uncertainty band. We need to use additional criteria do decide about the reliability of the final prediction intervals.
In addition to the coverage statistics, another useful statistics to evaluate the prediction intervals is the mean Winkler Interval Score (WIS) Winkler (1972).
# Coverage statistics
final.outputs %>%
count(covered) %>%
mutate(perc = n/sum(n)*100)# A tibble: 2 × 3
covered n perc
<lgl> <int> <dbl>
1 FALSE 19 21.1
2 TRUE 71 78.9# Final accuracy metrics in the original range
final.accuracy <- final.outputs %>%
summarise(n = n(),
rmse = rmse_vec(truth = observed, estimate = predicted),
bias = msd_vec(truth = observed, estimate = predicted),
rsq = rsq_trad_vec(truth = observed, estimate = predicted),
ccc = ccc_vec(truth = observed, estimate = predicted, bias = T),
rpiq = rpiq_vec(truth = observed, estimate = predicted),
coverage = sum(covered)/n*100,
wis = mean(wis))
final.accuracy# A tibble: 1 × 8
n rmse bias rsq ccc rpiq coverage wis
<int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 90 0.611 0.167 0.608 0.722 1.15 78.9 3.80# Final accuracy plot
perfomance.annotation <- paste0("Rsq = ", round(final.accuracy[[1,"rsq"]], 2),
"\nRMSE = ", round(final.accuracy[[1,"rmse"]], 2), " wt%",
"\nCoverage = ", round(final.accuracy[[1,"coverage"]], 2), "%",
"\nWIS = ", round(final.accuracy[[1,"wis"]], 2), " wt%")
p.final <- ggplot(final.outputs) +
geom_pointrange(aes(x = observed, y = predicted,
ymin = lower_PI, ymax = upper_PI,
color = covered)) +
geom_abline(intercept = 0, slope = 1) +
geom_text(aes(x = -Inf, y = Inf, hjust = -0.1, vjust = 1.2),
label = perfomance.annotation, size = 3) +
labs(title = "Soil Organic Carbon (wt%) test prediction",
x = "Observed", y = "Predicted", color = "PI95% covered:") +
theme_light() + theme(legend.position = "bottom")
# Making sure it we have a square plot
r.max <- max(layer_scales(p.final)$x$range$range)
r.min <- min(layer_scales(p.final)$x$range$range)
s.max <- max(layer_scales(p.final)$y$range$range)
s.min <- min(layer_scales(p.final)$y$range$range)
t.max <- round(max(r.max,s.max),1)
t.min <- round(min(r.min,s.min),1)
p.final <- p.final + coord_equal(xlim = c(t.min,t.max), ylim = c(t.min,t.max))
p.final